Seit Jahren fühlen sich Apple-Silicon-Macs in der professionellen AV-Branche wie ein Paradox an.
Auf der einen Seite sind sie absolute Monster, wenn es um Video-Playback und Rendering-Performance geht. Moderne Macs können problemlos mit den größten High-End-Medienservern am Markt konkurrieren. In vielen Szenarien übertreffen sie sie sogar.
Ein M4 Max kann unglaubliche Mengen an Echtzeit-Playback bewegen — bis zu 16 gleichzeitige 8K60-Streams in ProRes und NotchLC. Ein M2 Ultra geht noch weiter und schafft 22-26 gleichzeitige 8K-Streams, ohne auseinanderzufallen.
Und ehrlich gesagt ist dieses Performance-Niveau in klassischen Medienserver- Architekturen kaum zu finden.
Warum?
Weil die meisten Medienserver irgendwann zwischen Storage-Bandbreite, CPU-Transfers, GPU-Uploads oder PCIe-Limitierungen in Flaschenhälse laufen. Apple Silicon umgeht viele dieser Probleme durch seine Unified-Memory-Architektur und absurde interne Bandbreite.
Die Rendering-Leistung ist da. Die Playback-Leistung ist da. Die Effizienz ist da.
Aber Apple hat eine sehr wichtige Sache vergessen.
Professionelle synchronisierte Outputs.
Kein sauberer Frame Sync. Keine echten genlockten Display-Ausgänge. Kein eleganter Weg, riesige Custom-LED-Canvases zu bespielen.
Und in der Pro-AV-Welt ändert das alles.
Ja, es gibt EDID-Hacks. Ja, Tiled Displays können funktionieren. Ja, DisplayPort 1.4 und HDMI 2.1 können theoretisch beeindruckende Dinge leisten.
Aber in der Realität unterstützen viele professionelle LED-Prozessoren und Videosysteme diese Workflows entweder nicht sauber oder bringen andere schmerzhafte Einschränkungen mit.
Der gesamte Setup-Prozess wird dadurch fragil, kompliziert und ehrlich gesagt… nicht besonders professionell.
Die üblichen Kompromisse
Dann gibt es SDI-basierte Lösungen wie Blackmagic DeckLink-Karten.
Aber auch sie bringen eigene Kompromisse mit:
- 8K bedeutet oft nur YUV-Farbraum.
- Verläufe leiden sichtbar.
- Die Latenz steigt deutlich.
- Custom Resolutions werden fast unmöglich.
Und sobald man mit massiven LED-Canvases arbeitet, werden diese Kompromisse sehr sichtbar.
Wir sprechen hier nicht von einfachen 4K-Screens.
Wir sprechen von LED-Wänden, die 40 oder 50 Meter breit sind.
Wände mit 2.6mm Pitch, bei denen 19200×1920-Canvases nicht mehr in klassische Workflows passen. Und es wird noch schwieriger, sobald man in Richtung 1.9mm oder 1.5mm Pixel Pitch geht.
Den Canvas herunterzuskalieren?
Nein. Nicht akzeptabel.
In den letzten sechs Jahren waren wir im Grunde von einer einzigen Frage besessen:
Wie bringen wir endlich die unglaubliche Rendering-Leistung von Apple-Silicon-Macs ohne Kompromisse auf ultra-breite professionelle LED-Systeme?
Denn ehrlich gesagt… es war frustrierend.
Der ShowMotion-Blickwinkel
Wir betreiben eine LED-Rental- und Produktionsfirma in Berlin, und neben der Hardware fahren wir viele Shows auch selbst. Dieses Problem war für uns also nie theoretisch. Wir sind in realen Produktionen ständig gegen diese Grenzen gelaufen.
Gleichzeitig haben wir im letzten Jahr unsere eigene Medienserver-Plattform für macOS entwickelt: SHOWMOTION.
Unser ursprünglicher Fokus lag stark auf IP-basierten Workflows:
- IPMX
- ST2110
- Ultra-Low-Latency-Video-Transport
- GPU-Rendering-Pipelines
- fortgeschrittene Routing-Systeme
- moderne Metal-basierte Architekturen
Auf diesem Weg mussten wir sehr tief in Themen eintauchen, die die meisten Menschen nie anfassen: Frame Buffers, Metal Textures, DMA-Transfers, Shared-Memory-Systeme, FPGA-Workflows, GPU-Synchronisation und Low-Level-Transportarchitekturen.
Die Wendung spät in der Nacht
Dann, vor ungefähr einer Woche, während einer dieser Late-Night-Brainstorming-Sessions, in denen man verzweifelt nach Lösungen für unmögliche Probleme sucht, stolperten wir über Scotts Blogpost.
Scott beschrieb, wie er es geschafft hatte, eine NVIDIA RTX GPU über Thunderbolt in eine QEMU-VM mit Linux ARM64 auf Apple Silicon durchzureichen.
Die Idee allein war schon verrückt. Er baute einen macOS Driver Stack, der nicht unterstützte NVIDIA-Hardware vom macOS-Host lösen und direkt in der Guest-VM verfügbar machen konnte, als wäre sie native Hardware.
Sein Ziel war Gaming.
Und ehrlich gesagt waren die Ergebnisse für Gaming gemischt. ARM64 Linux zu betreiben, während viele Workloads in Richtung x86-Umgebungen übersetzt werden, bringt viel Overhead mit. Die Performance war interessant, aber nicht revolutionär.
Aber wir sahen sofort etwas anderes.
Nicht Gaming. Outputs.
In dem Moment, in dem wir realisierten, dass eine echte NVIDIA GPU in einer Guest-VM auf einem Apple-Silicon-Mac laufen konnte, stand sofort eine Frage im Raum:
Können wir gerenderte Frames irgendwie direkt in diese Guest-GPU bekommen?
Von IP-Streaming zu Shared Buffers
Zuerst versuchten wir den naheliegenden Ansatz: IP-Streaming.
Aber sehr schnell stießen wir auf harte Bandbreitenlimits. Selbst hochoptimierte virtuelle Netzwerk-Setups kamen über ungefähr 14 Gbit/s kaum hinaus. Die Virtualisierungsschichten und Netzwerk-Stacks wurden schlicht zum Bottleneck.
Also begannen wir, Scotts DMA- und Buffer-Allocation-Ansatz viel genauer zu studieren.
Mit etwas Hilfe von Codex gelang es uns, innerhalb eines einzigen Tages ein Shared-Buffer-Passthrough-System zu bauen.
Plötzlich konnten wir Buffer mit mehr als 1.5 GB direkt zwischen Metal und der Guest-VM verfügbar machen.
Ab dort wurde die Idee überraschend einfach:
- Eine Metal Texture nehmen.
- Sie in einen Shared Buffer legen.
- Den Buffer in der Linux-Guest-VM verfügbar machen.
- CUDA direkt darauf zugreifen lassen.
- Das Bild über die NVIDIA DisplayPort-Ausgänge ausgeben.
In der Theorie einfach. In der Realität extrem schmerzhaft.
Denn sobald man in 8K und darüber hinaus geht, werden CPU-Copies katastrophal. Ein paar unnötige Memory Copies zerstören Performance und Latenz vollständig.
CPU-Copies mussten komplett verschwinden.
Metal → Shared Buffer → Guest VM → CUDA
Nach vielen schmerzhaften Iterationen hatten wir schließlich eine vollständig funktionierende Pipeline mit effektiv null CPU-Copies.
Die CPU-Auslastung wurde fast vernachlässigbar — ungefähr ein halber CPU-Core für Synchronisation, Speicheradressierung und Timing-Management.
Vollkommen akzeptabel.
Und plötzlich… passierte das Unmögliche.
SHOWMOTION renderte eine 16384×2160 Texture. CUDA empfing sie in der Guest-VM. Die NVIDIA GPU teilte das Bild in vier perfekt synchronisierte DisplayPort-Tiles.
100% frame-synchronisiert.
Es fühlte sich unwirklich an.
Nach Jahren der Suche hatten wir plötzlich ein System, das wirklich funktionierte.
Die Bandbreitenwand
Natürlich tauchte sofort das nächste Problem auf.
Bandbreite.
Eine vollständige RGBA10-Texture in diesen Auflösungen benötigt inklusive Overhead etwa 140 Gbit/s Bandbreite.
Thunderbolt 5 unterstützt theoretisch 80 Gbit/s. In der Realität liegt die nutzbare Bandbreite eher bei etwa 55 Gbit/s.
Das bedeutete: Unkomprimierter Transport war unmöglich.
Und auf YUV-Kompression wie in klassischen Broadcast-Workflows zurückzufallen, war für uns keine Option.
Wir wollten volle RGBA-Qualität.
Also machten wir weiter.
Inspiriert von IPMX und wavelet-basierten Transportsystemen begannen wir, unseren eigenen Ultra-Low-Latency-Wavelet-Codec zu entwickeln, optimiert genau für diesen Workflow.
Die Anforderungen waren brutal:
- extrem niedrige Latenz
- visuell verlustfreie Qualität
- fast keine CPU-Nutzung
- minimaler Metal- und CUDA-Compute-Overhead
- schnell genug für Live-Playback
Und irgendwie… funktionierte es.
Wir schafften es, ungefähr 140 Gbit/s RGBA10-Bandbreite auf etwa 25-55 Gbit/s zu reduzieren und dabei visuell verlustfrei zu bleiben.
Latenz?
- etwa 3ms Encode
- etwa 0.9ms Decode
Unsere gesamte Pipeline — von der Metal Render Texture bis zum synchronisierten NVIDIA DisplayPort Output — liegt nun bei etwa 16-20ms Gesamtlatenz.
Ungefähr ein Frame.
Je nach Synchronisationsstrategie kann für deterministischen Sync noch ein zweiter Frame nötig sein. Aber ehrlich?
Zwei Frames Latenz für massive 8K+ synchronisierte RGBA10-Canvases sind in realen LED-Workflows absolut akzeptabel.
Nach sechs Jahren… hatten wir endlich eine echte Lösung.
Und gerade sind wir an dem Punkt: "Lasst uns aufhören zu benchmarken und das endlich auf echten Shows ausprobieren."
Der Mac-Pro-Test
Aber natürlich haben wir dort nicht aufgehört.
Wir holten unseren alten M2 Ultra Mac Pro aus dem Lager und installierten eine NVIDIA RTX A4000 direkt über volles PCIe x16 in der Maschine.
Driver Stack installiert. Guest VM gebootet. Frame Pool verbunden. Das SHOWMOTION-Bild erschien sofort.
Und plötzlich:
Volle unkomprimierte RGBA10-Textures funktionierten perfekt.
Keine Thunderbolt-Limitierungen mehr.
Visuell gibt es fast keinen Unterschied zu unserem Wavelet-Transport-System — außer, dass der unkomprimierte Workflow noch ein paar Millisekunden schneller ist.
Die einzige verbleibende Herausforderung ist Synchronisations-Buffering. Echter deterministischer Frame Sync bei 60p profitiert weiterhin von einem zusätzlichen Sync-Frame.
Aber ehrlich? Das ist völlig in Ordnung.
Warum diese Architektur Sinn ergibt
Denn was uns plötzlich klar wurde:
Diese Architektur ergibt tatsächlich Sinn.
Apple Silicon ist wahrscheinlich eine der besten Echtzeit-Rendering-Plattformen, die je gebaut wurden.
NVIDIA-Quadro-Hardware ist immer noch eines der besten professionellen synchronisierten Output-Systeme, die je gebaut wurden.
Die Kombination beider Welten erschließt plötzlich etwas, das keines der beiden Ökosysteme allein erreichen konnte.
Und diesen Montag wird es noch interessanter.
Unsere zweite RTX A4000 kommt an.
Das bedeutet: SLI-Bridge-Tests im Mac Pro.
8 synchronisierte 4K-Outputs aus einem einzigen Apple-Silicon-Mac-Pro? Wir glauben wirklich, dass das möglich ist.
Und auf Mac-Studio-Systemen: 8 synchronisierte 4K-Outputs über zwei Thunderbolt-4/5-Links mit unserer Wavelet-Transportarchitektur.
Auch das sieht sehr realistisch aus.
Was passiert als Nächstes?
Wir haben unseren Driver Stack bereits bei Apple eingereicht, in der Hoffnung, ihn sauber signiert zu bekommen.
Der Plan ist, später Folgendes zu veröffentlichen:
- den Driver Stack
- das Control Panel
- das SDK
für Entwickler und Pro-AV-User.
Wollen wir damit Geld verdienen?
Natürlich.
Aber ehrlich gesagt ist unser eigentliches Geschäft LED-Produktionen und Live-Events.
Was wir wirklich wollen, ist größer:
Wir wollen, dass das macOS-Ökosystem endlich ein ernstzunehmender Player im High-End Pro AV wird.
Wir wollen, dass Software wie:
- Resolume
- Millumin
- TouchDesigner
- und viele andere großartige macOS-Tools
endlich Zugriff auf echte synchronisierte professionelle Outputs bekommt.
Denn Apple Silicon hat das Rendering-Problem schon vor Jahren gelöst.
Vielleicht ist das endlich das fehlende Stück, das auch das Output-Problem löst.
PS
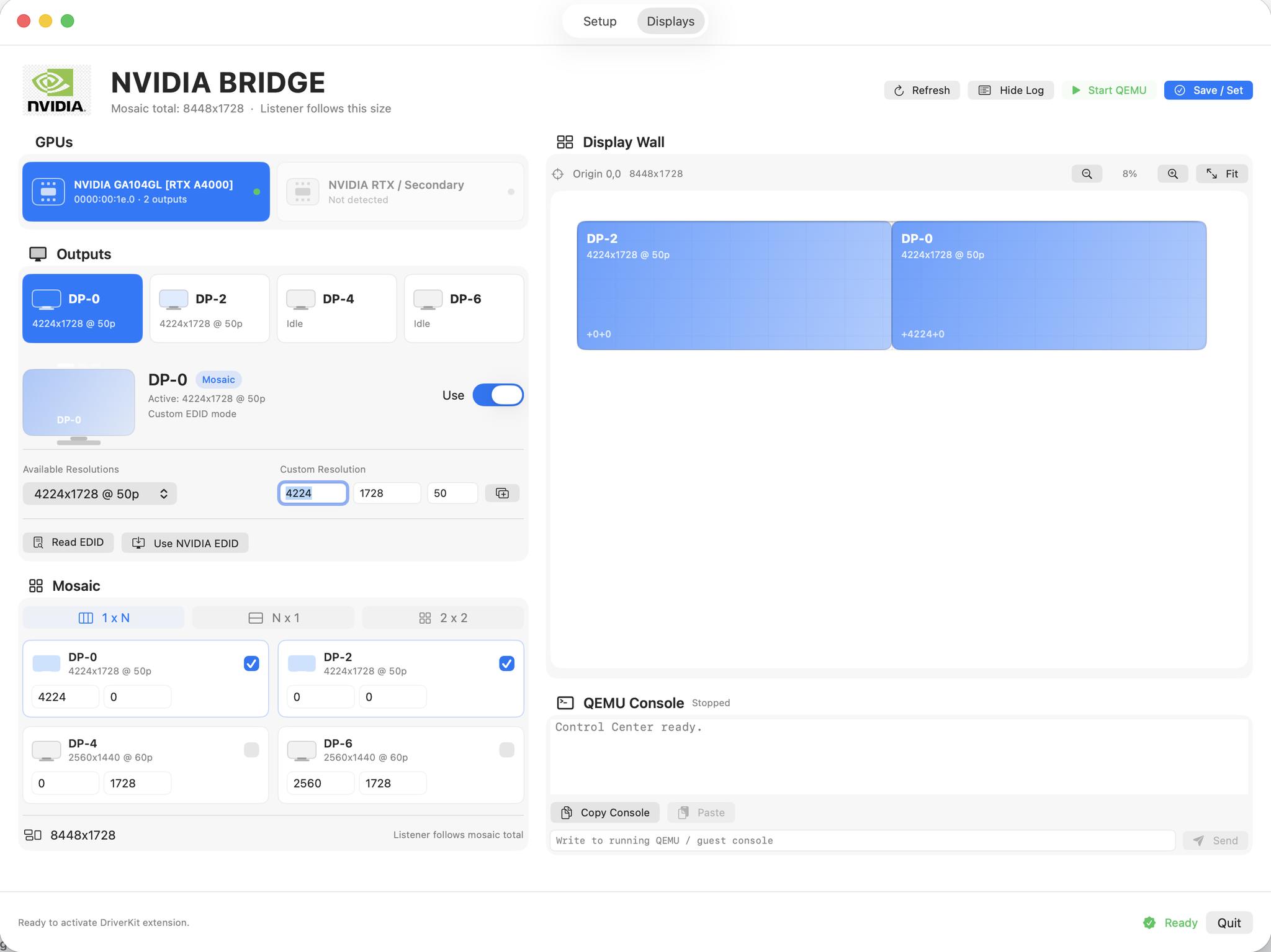
Ja, Custom Resolutions funktionieren perfekt.
Du brauchst ein NVIDIA-Mosaic-Setup mit 8448×1728?
Kein Problem.
Wir haben NVIDIA Quadro EDID Handling, Custom Timings, Mosaic Management und Output Lock bereits direkt in den Workflow integriert.
Baust du Pro-AV-Workflows auf Apple Silicon?
Sprich mit uns